Intro
并查集(Union Find):一种树型的数据结构,用于处理一些不交集(Disjoint Sets)的合并及查询问题。不交集指的是一系列没有重复元素的集合。 并查集主要支持两种操作:
- 合并(Union):将两个集合合并成一个集合
- 查找(Find):确定某个元素属于哪个集合。通常是返回集合内的一个「代表元素」
这里我理解,可以当成是对Set(集合)的一种能力扩充和查询优化。大部分支持Set数据结构的高级编程语言,其实已经可以做到查询某元素是否在该集合内,以及合并两个集合。但是想快速知道元素a和元素b是否同属于一个集合还不太容易直接得到。
综上,通常「并查集」数据结构支持以下这几个操作api:
- 合并
union(x, y): 将集合 x 和集合 y 合并成一个集合。 - 查找
finx(x): 查找元素x属于那哪个集合 - 查找
is_connected(x, y): 查询元素x和y是否在同一个集合中
Implementation
1. 快速查询
我们基于数组来实现,用数组下标来表示集合中的元素,数组元素来表示集合编号。
对于这样的一个并查集,我们有如下操作:
- 初始化:将数组下标索引值作为每个元素的集合编号。所有元素的id都是唯一的,代表着每个元素单独属于一个集合。
- 合并操作:将其中一个集合中的所有元素id(集合编号) 改成另外一个集合的集合编号。
- 查询操作:如果两个集合的集合编号一致,则说明在同一个集合。
举例来说:我们使用数组来表示一系列集合元素 {0},{1},{2},{3},{4},{5},{6},{7},初始化时如下图所示。
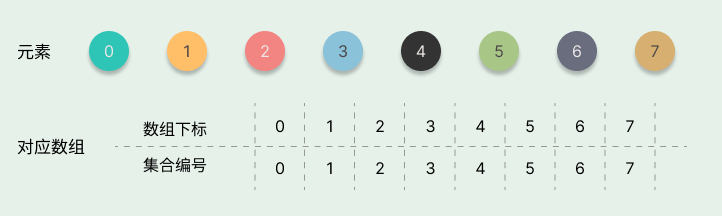
当我们进行一系列的合并操作后,比如合并后变为 {0},{1,2,3},{4},{5,6},{7},合并操作的结果如下图所示。
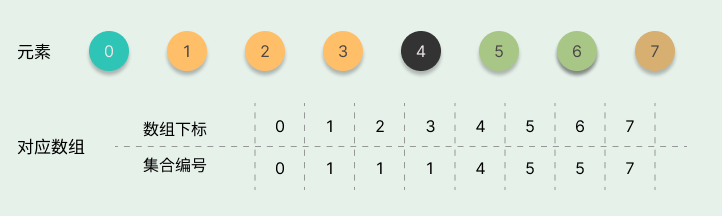
在快速查询的实现思路中,单次查询操作的时间复杂度是$O(1)$,而单次合并操作的时间复杂度为$O(n)$(每次合并操作需要遍历数组)。两者的时间复杂度相差得比较大,完全牺牲了合并操作的性能。因此,这种并查集的实现思路并不常用。
2. 快速合并
使用森林(若干颗树)来存储所有集合,实现快速合并。每一棵树代表一个集合,树上的每个节点都是一个元素,树根节点为这个集合的代表元素。
和普通树形结构(父节点指向子节点)不同的是,基于森林实现的并查集中,树中的子节点是指向父节点的。
我们仍然可以使用一个数组$fa$来记录这个森林。我们用 $fa[x]$ 来保存$x$的父节点的集合编号,代表着元素节点 $x$ 指向父节点 $fa[x]$。
对于这样的并查集,我们有如下操作
-
当初始化时,$fa $值赋值为下标索引 $x$。
-
在进行合并操作时,只需要将两个元素的树根节点相连接($fa[root1] = root2$)即可。而在进行查询操作时,只需要查看两个元素的树根节点是否一致,就能知道两个元素是否属于同一个集合。
-
查找操作时:分别从两个元素开始,通过数组 $fa$存储的值,不断递归访问元素的父节点,直到到达树根节点。如果两个元素的树根节点一样,则说明它们属于同一个集合;如果两个元素的树根节点不一样,则说明它们不属于同一个集合。
同样我们使用数组来表示一系列集合元素 {0},{1},{2},{3},{4},{5},{6},{7},初始化时如下图所示。
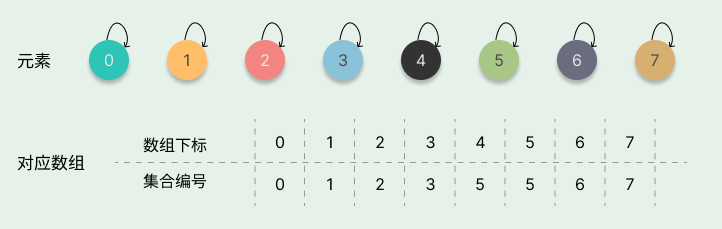
当我们进行一系列的合并操作后,比如 union(4, 5)、union(6, 7)、union(4, 7) 操作后变为{0},{1},{2},{3},{4,5,6,7},合并操作的步骤及结果如下图所示。

从上图中可以看出,在进行一系列合并操作后$fa[fa[4]] == fa[5] == fa[6] == f[7]$,即 4、5、6、7 的元素根节点编号都是4,说明这4个元素同属于一个集合。
使用「快速合并」思路实现的并查集代码(Swift.version)如下:
public class UnionFind {
private var fa = [Int](0...n)
public func find(element: Int) -> Int {
var x = element
while fa[x] != x {
x = fa[x]
}
return x
}
public func union(first: Int, second: Int) -> Bool {
let rootX = fa[first]
let rootY = fa[second]
if rootX == rootY {
return false
}
fa[rootX] = rootY
return true
}
public func isConnected(first: Int, second: Int) -> Bool {
return find(element: first) == find(element: second)
}
}
Advance
路径压缩
在集合很大或者树很不平衡时,使用上述「快速合并」思路实现并查集的代码效率很差,最坏情况下,树会退化成一条链,单次查询的时间复杂度高达$O(n)$。并查集的最坏情况如下图所示:
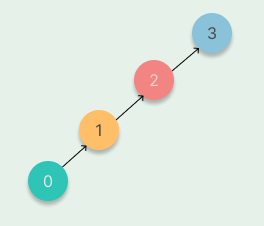
为了避免出现最坏情况,一个常见的优化方式是「路径压缩」。
路径压缩(Path Compression):在从底向上查找根节点过程中,如果此时访问的节点不是根节点,则我们可以把这个节点尽量向上移动一下,从而减少树的层树。这个过程就叫做路径压缩。
路径压缩有两种方式:一种叫做「隔代压缩」;另一种叫做「完全压缩」。
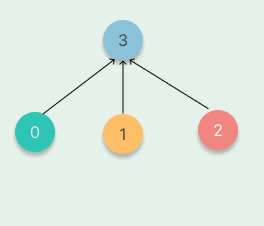
隔代压缩
在进行Find操作遍历某条路径时,不断地将当前节点指向其祖父节点(父亲节点的父亲节点),从而减少树的深度。 下面是一个「隔代压缩」的例子

完全压缩
完全压缩:在查询时,把被查询的节点到根节点的路径上的所有节点的父节点设置为根节点,从而减小树的深度。也就是说,在向上查询的同时,把在路径上的每个节点都直接连接到根上,以后查询时就能直接查询到根节点。 相比较于「隔代压缩」,「完全压缩」压缩的更加彻底。下面是一个「完全压缩」的例子
按秩合并
因为路径压缩只在查询时进行,并且只压缩一棵树上的路径,所以并查集最终的结构仍然可能是比较复杂的。为了避免这种情况,另一个优化方式是「按秩合并」
按秩合并(Union By Rank):指的是在每次合并操作时,都把「秩」较小的树根节点指向「秩」较大的树根节点。
这里的「秩」有两种定义,一种定义指的是树的深度;另一种定义指的是树的大小(即集合节点个数)。无论采用哪种定义,集合的秩都记录在树的根节点上。 按秩合并也有两种方式:一种叫做「按深度合并」;另一种叫做「按大小合并」。
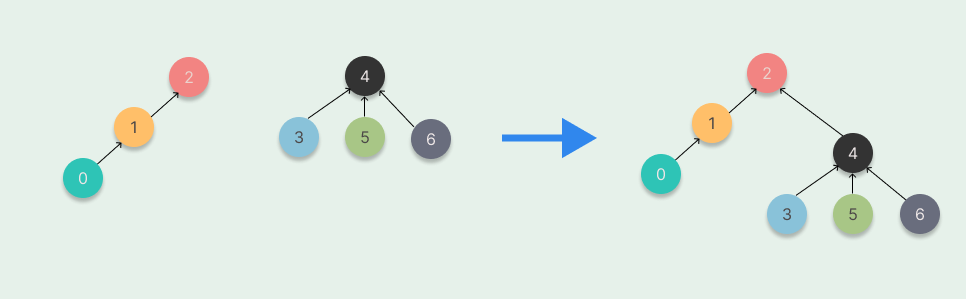
按深度合并
按深度合并(Unoin By Rank):在每次合并操作时,都把「深度」较小的树根节点指向「深度」较大的树根节点。
我们用一个数组 rank 记录每个根节点对应的树的深度(如果不是根节点,其rank 值相当于以它作为根节点的子树的深度)。初始化时,将所有元素的rank 值设为1。在合并操作时,比较两个根节点,把rank 值较小的根节点指向rank值较大的根节点上合并.
下面是一个「按深度合并」的例子
按大小合并
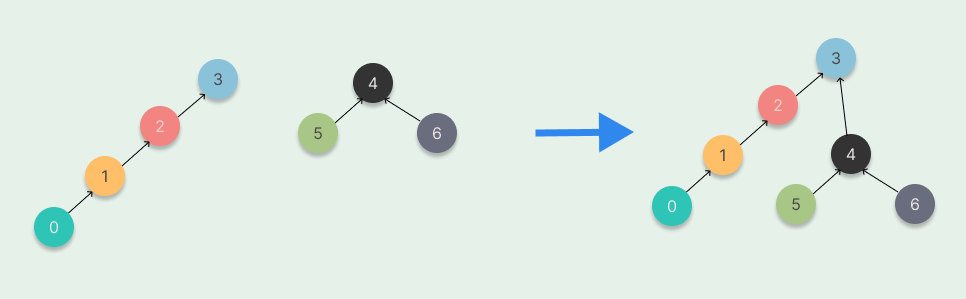
按大小合并(Unoin By Size):这里的大小指的是集合节点个数。在每次合并操作时,都把「集合节点个数」较少的树根节点指向「集合节点个数」较大的树根节点。
我们用一个数组 size 记录每个根节点对应的集合节点个数(如果不是根节点,其
size值相当于以它作为根节点的子树的集合节点个数)。初始化时,将所有元素的size 值设为1。在合并操作时,比较两个根节点,把size值较小的根节点指向size值较大的根节点上合并。
下面是一个「按大小合并」的例子。
Complexity
- 空间复杂度:$O(n)$
- 时间复杂度:理想情况下接近于$O(1)$ , 最坏情况是$O(m×α(n))$
证明可以参考:https://oi-wiki.org/ds/dsu/
Model Code
使用完全压缩和按大小合并
public struct UnionFindWeightedQuickUnionPathCompression<T: Hashable> {
private var index = [T: Int]() // 元素和集合的映射
private var parent = [Int]() // 集合编号的指向关系 parent[a] = b => a 指向 b
private var size = [Int]() // 集合节点个数
public init() {}
public mutating func addSetWith(_ element: T) {
index[element] = parent.count
parent.append(parent.count)
size.append(1)
}
/// Path Compression.
private mutating func setByIndex(_ index: Int) -> Int {
if index != parent[index] {
parent[index] = setByIndex(parent[index])
}
return parent[index]
}
public mutating func setOf(_ element: T) -> Int? {
if let indexOfElement = index[element] {
return setByIndex(indexOfElement)
} else {
return nil
}
}
public mutating func unionSetsContaining(_ firstElement: T, and secondElement: T) {
if let firstSet = setOf(firstElement), let secondSet = setOf(secondElement) {
if firstSet != secondSet {
if size[firstSet] < size[secondSet] {
parent[firstSet] = secondSet
size[secondSet] += size[firstSet]
} else {
parent[secondSet] = firstSet
size[firstSet] += size[secondSet]
}
}
}
}
public mutating func inSameSet(_ firstElement: T, and secondElement: T) -> Bool {
if let firstSet = setOf(firstElement), let secondSet = setOf(secondElement) {
return firstSet == secondSet
} else {
return false
}
}
}
...